
By Gustavo Brito
In fraud detection, time is the real currency, both for operators buried in false positives and fraudsters exploiting detection lag. In this IvyInsights piece, Gustavo Brito, Data Scientist at Ivy Partners, breaks down how machine learning architectures don’t replace human analysts, they buy back their time for the work that actually requires expertise.

A transaction flagged at 9:03 AM. By 9:47 AM, the operator has searched the cardholder’s name, cross-referenced the billing address with three databases, and checked purchase history against known fraud patterns. The verdict: false positive. Forty-four minutes spent on a legitimate transaction. Meanwhile, seven more alerts wait in the queue.
This scene plays out thousands of times daily across financial institutions. And while operators work through each case methodically, fraudsters move in real time.
The Scale of the Problem
This manual approach cannot keep pace with modern fraud.
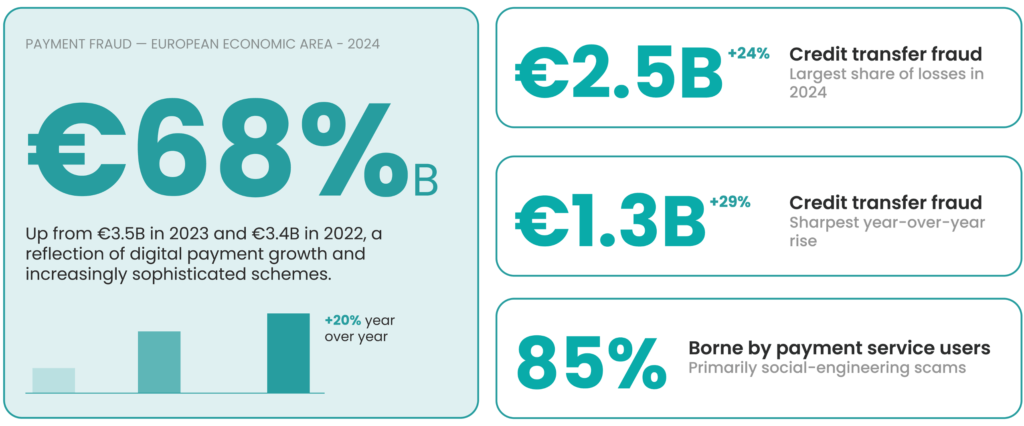
Payment fraud in the European Economic Area reached €4.2 billion in 2024, up from €3.5 billion in 2023 and €3.4 billion in 2022, according to the joint report published by the European Central Bank (ECB) and the European Banking Authority (EBA) in December 2024. The 20% year-over-year increase reflects both the growth of digital payments and the increasing sophistication of fraud schemes.
The breakdown reveals where the damage concentrates. Credit transfer fraud totaled €2.5 billion in 2024, a 24% increase from the previous year. Card payment fraud reached €1.3 billion, up 29% year-over-year. Most concerning: payment service users bore approximately 85% of credit transfer fraud losses, primarily as a result of social engineering scams that tricked users into initiating fraudulent transactions themselves.
Financial institutions respond by staffing fraud operations teams that manually review flagged transactions. These analysts perform repetitive, time-intensive work: verifying identities, checking addresses, cross-referencing behavioral patterns. The bottleneck is not expertise, it’s volume.
Machine Learning Does Not Replace Operators, It Elevates Them
As someone working in data science in this space, I see daily how machine learning models uncover patterns that would take human analysts hours, sometimes weeks, to identify manually. But the goal is not to remove human judgment from the process, the goal is to redirect it toward where it matters most.
Models excel at filtering noise: scoring transactions by risk, prioritizing high-probability fraud, and surfacing the signals buried in vast data volumes. What they cannot do is make the final call on ambiguous cases, weigh contextual factors that fall outside training data, or communicate with customers. That remains human work.
The value proposition is straightforward: amplify operator expertise by automating the preliminary screening that currently consumes most of their time. Instead of reviewing every flagged transaction equally, analysts can focus on the cases where their judgment genuinely adds value.
Time as the Core Benefit
The main improvement machine learning brings to fraud detection is time. Time that operators save on repetitive screening. Time that fraudsters lose when detection windows shrink from hours to seconds. Time that can be redirected toward higher-value decisions, complex investigations, and process improvement.
Faster detection also reduces financial exposure. A transaction caught in 30 seconds costs less to reverse than one discovered 30 hours later. The compounding effect of speed, across thousands of daily transactions, translates directly to reduced losses and operational efficiency.

Enabling Architecture: Event-Driven Design
Achieving real-time detection at scale requires specific architectural choices. Event-driven architecture (EDA) has emerged as a foundational framework for implementing real-time fraud detection in financial services. Research published in the World Journal of Advanced Engineering Technology and Sciences documents how financial institutions adopting event-driven architectures have achieved significant improvements in system responsiveness, with substantial reductions in processing latency compared to traditional request-response models.
The core components form a processing pipeline:
This architecture offers three advantages over batch processing:
- It enables detection at the moment of transaction rather than hours later.
- It scales horizontally as transaction volume grows.
- It allows model replacement without system downtime, supporting continuous improvement as fraud patterns evolve.
The Feedback Loop: Keeping Models Accurate
A critical addition to this architecture is the model feedback layer. When operators confirm or override a model’s scoring, that outcome feeds back into the training pipeline. This closes the loop: the model learns from its mistakes, adapts to new fraud patterns, and improves over time.
Without feedback, models decay. The ECB/EBA report highlights this dynamic: strong customer authentication remains effective against the fraud types it was designed to mitigate, but new types of fraud are on the rise, particularly payer manipulation schemes. Fraudsters adapt. Models must adapt faster.
Mixing two patterns: Hybrid rule and machine learning systems
While machine learning systems can perform well on their own, they can be opaque and slow to adapt operationally. On the other hand, pure rule-based systems can feel too rigid and easy to evade. This led to the development of a hybrid architectural pattern: hybrid rule-based and machine learning systems. This pattern balances the control and speed of rule-based systems with the precision and adaptability of pure ML systems.
This architectural pattern offers several implementation approaches:
1. Sequential Pattern
In the sequential pattern, the workflow is straightforward: first, the transaction passes through the rules engine. If a rule is broken, the transaction is immediately blocked. Then it passes through the machine learning model to catch more nuanced cases that simple rules cannot detect.

This pattern has clear benefits: it reduces the workload on the ML engine and ensures that critical rules are always followed and enforced.
2. Parallel Scoring Pattern
In parallel scoring, both the ML model output and the rule-based decision contribute to the final score.
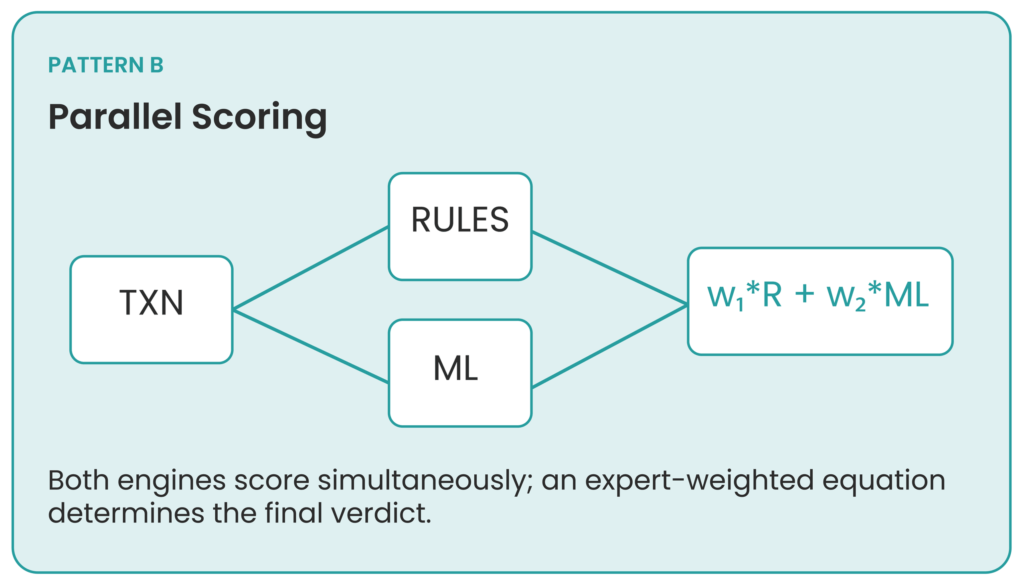
For example: Consider a single transaction. This transaction follows the rules, giving it a rule score of 0. But the machine learning model finds this transaction suspicious, assigning it a score of 0.91. After receiving both values, the system must decide which to trust more. This can be done with a simple equation like:
Decision Score = w₁ × Rule Score + w₂ × ML Score
Where w₁ and w₂ are predetermined values chosen by experts.
This pattern offers clear advantages: it is more flexible, has better accuracy on average, and supports weighted decision-making.
3. Rules as Features
This last pattern can be considered a more advanced version of hybrid rule-based and machine learning systems.
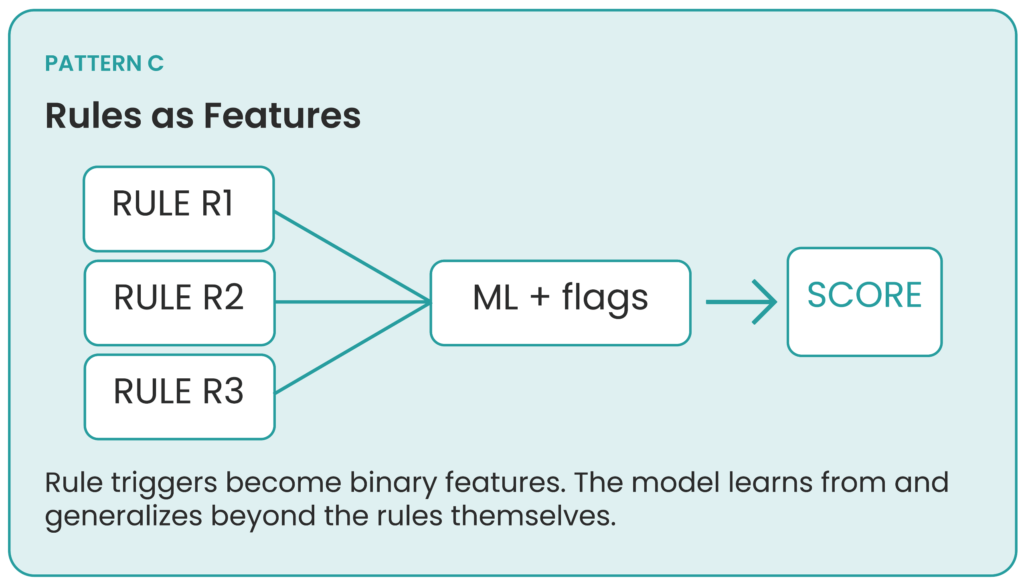
Instead of using rules as transaction blockers, we use them as features, as the title of the pattern suggests. This works as follows:
Rule is triggered → Suspicious Flag = 1
This feature is then used as an input for the machine learning model. This helps the model over time tune itself to the rules it is being fed, improving not only its ability to prioritize transactions with these flags as more dangerous, but also to generalize its decisions to make them more robust.
Explainability: What Makes a Model Decide
A critical layer in hybrid systems is the explainability layer. This is the layer that translates what the model is “thinking” into human language, making it possible for operators and even less technical employees to understand the reasoning behind the decision to flag a transaction as fraudulent.
This layer is extremely important to data scientists and analysts as well. Model decisions can become “black boxes” after the training period, making interpretation difficult. Explainability serves three functions: it increases regulatory compliance by ensuring the model is not making biased decisions; it builds customer trust, since we can explain to a customer why their transaction was blocked; and it improves data scientists’ workflow, allowing more thorough analysis of the model’s historical decisions and identification of improvement opportunities.
The opportunity in fraud detection is not automation for its own sake. It is the reallocation of human attention from mechanical screening to the judgment calls that actually require expertise. Machine learning handles volume. People handle nuance. The architecture exists to make that division of labor possible at scale. What makes this shift sustainable is explainability: the ability to understand, trust, and improve the system over time. Without it, even the most sophisticated model remains a black box that operators will route around rather than rely on.
References
Confluent. (2025). Real-time fraud detection: Use case implementation [White paper]. https://www.confluent.io/resources/white-paper/real-time-fraud-detection-use-case-implementation/
European Banking Authority & European Central Bank. (2024, December). 2025 report on payment fraud [Joint report]. https://www.eba.europa.eu/publications-and-media/press-releases/joint-eba-ecb-report-payment-fraud-strong-authentication-remains-effective-fraudsters-are-adapting
European Central Bank. (2024, December 15). Joint EBA-ECB report on payment fraud: Strong authentication remains effective but fraudsters are adapting [Press release]. https://www.ecb.europa.eu/press/pr/date/2025/html/ecb.pr251215~e133d9d683.en.html
Harris, M., et al. (2025). Event-driven fraud detection system: A cloud-native architecture for real-time transaction analysis. World Journal of Advanced Engineering Technology and Sciences, 15(02), 1684–1693. https://wjaets.com/sites/default/files/fulltext_pdf/WJAETS-2025-0701.pdf
About the Author

Gustavo Brito is a Data Scientist at Ivy Partners with four years of experience leveraging machine learning and data analytics to support strategic decision-making in the energy and banking sectors. He has a solid foundation in statistical modeling, predictive analytics, data engineering, and data visualization, having contributed to projects such as detecting fraudulent transactions and optimizing power plant performance. Driven by a passion for turning data into meaningful impact, Gustavo applies a practical and results-focused approach to improve outcomes and optimize resources within organizations.