
By Matthieu Eynard Longuet
Resilience can light up dashboards, but only recovery tells the truth. In this piece, Matthieu Eynard Longuet, Storage Engineer (Architecture & DevOps) at Ivy Partners, shares a lesson from a homelab setback that echoes in enterprise environments: backup architectures can look perfect on paper, yet recovery success ultimately depends on restore readiness.

I Thought I Had Done Everything Right
My Homelab configuration was pretty solid:
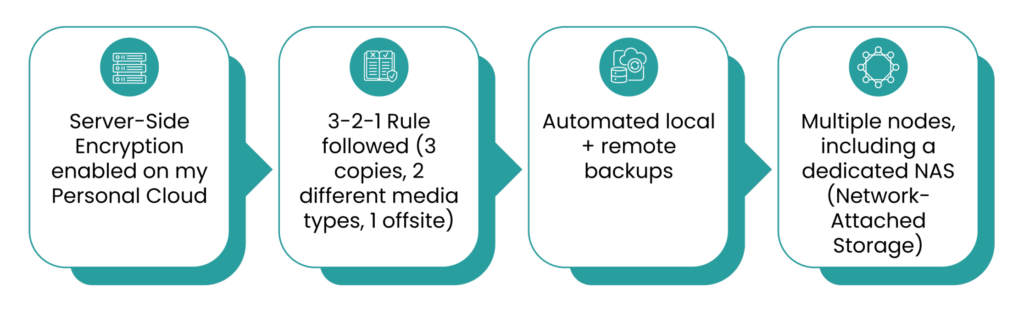
I was confident. I genuinely believed my data was safe. Until a system crash forced me to restore. And that’s when the trouble started.
The 3-2-1 Rule: A Checklist Masquerading as a System
For those less familiar with backup strategies, the 3-2-1 rule is a long‑standing best practice: keep three copies of your data, on two different media types, with at least one copy offsite.
On paper, it’s simple. In practice, it’s often treated as a checklist rather than a system. And that distinction matters more than most people realize.
My backup process had successfully saved my files but had excluded the database containing the metadata and hashes required. That database is what links each encrypted file to the correct decryption key.
And the result? Terabytes of data replicated across 3 different locations. All perfectly unreadable.
I had the decryption keys. I had the raw files. But without that specific database (which mapped the encryption metadata to the files), it was like holding many keys to many vaults… without knowing which one is the right one.
The Invisible Scope Problem: What Gets Backed Up (And What Doesn’t)
This wasn’t a rare edge case. It’s a systemic problem that appears in backup architectures across enterprises worldwide.

Back to my story, or rather, my personal nightmare: I contacted support. I scoured the forums. The answer was unanimous: technically possible, practically unfeasible. The complexity made manual restoration a lost cause.
I lost five years of personal projects and documents. Including the builds of a video game I presented at Paris Games Week 2019. Years of creation, gone up in smoke.
The worst part is that I thought I had done everything right. I enabled encryption believing my keys would be enough. No one warned me, not even the documentation at the time, that the database was the critical link in the chain.
The Enterprise Reality: False Confidence at Scale
Today, working on mission-critical infrastructure, I see this trap everywhere.
Organizations demand backups. Dashboards light up green. Compliance requirements get checked off. But restoration – the only thing that actually matters – is often an afterthought.
I see it repeatedly:
- Backup success measured by completion, not recoverability.
- Servers backed up without their configuration stores.
- Encrypted volumes backed up without key orchestration mechanisms.
- Databases replicated without ensuring transactional consistency.
According to the 2024 Business Backup Survey, 84% of IT decision-makers say their organizations rely on cloud drive services for off-site backup. But cloud drives don’t always protect against file corruption or accidental deletion, especially when retention and immutability controls aren’t in place. They’re convenient, but they don’t guarantee true backup-level recoverability.
And even when companies do have “proper” backup systems in place, another issue shows up: they don’t always verify that those backups actually work. Various industry surveys indicate that 34% of companies never test their tape backups. Even more concerning, among those that do test, around 77% report discovering failures during the process.
We obsess over RPOs (Recovery Point Objectives), geographic replication, and storage redundancy. Yet we often neglect application consistency: ensuring that the data, the database, and the encryption mechanisms are backed up in a synchronised state, allowing them to function immediately upon restoration.
Backing up encrypted storage without backing up the mechanisms required to decrypt it is worse than doing nothing. It creates a false sense of security.
The Cost of This Illusion
As a result, the financial impact is quite significant. What looks like “good enough” backup coverage on paper can quickly turn into operational paralysis the moment something goes wrong. And the numbers make that reality hard to ignore:

In other words: the real danger isn’t the incident itself, again it is the false sense of security before it happens. Because when cloud drives are mistaken for backups, or when backups are never tested, organizations don’t just risk losing files. They risk losing time, trust, revenue, and in many cases, the business.
The Ransomware Dimension: Why Backup Scope Matters More Than Ever
According to Sophos’ 2025 State of Ransomware Report, just 49% of organizations that paid the ransom actually recovered their data. Representing a slight decline from 2024 (56%), but it remains the second-highest ransom payment rate in six years. Even more troubling: organizations are increasingly using multiple recovery methods simultaneously, with 47% of victims now employing both ransom payments and backups, suggesting that neither strategy alone is sufficient.
The median ransom payment fell to $1 million in 2025, down 50% from $2 million in 2024. Yet even at lower payment amounts, recovery isn’t guaranteed. On average, 826 organizations that paid ransom negotiated payments equal to 85% of the initial demand, but they still faced the uncertainty of whether that payment would yield actual data recovery.
Here’s the critical insight that can change everything: an estimated 97% of organizations that had data encrypted were able to recover it, regardless of ransom payment. This recovery includes backups, decryption tools, or ransomware payments combined. But the most powerful finding is this: 53% of victims recovered within one week when they had tested, reliable backups, a significant jump from just 35% in 2024.
Organizations with incomplete backups face a terrible choice: pay ransom with no guarantee of recovery, or attempt restoration from incomplete backups and fail. Those with complete, tested, immutable backup architectures have a third option: recover without paying.
The difference between organizations that survive ransomware and those that don’t isn’t luck, and it isn’t ransom negotiation skill. It’s the completeness, testability, and immutability of their backup architecture.
The Testing Gap: The Distance Between Confidence and Capability
Here’s where the gap between intention and reality becomes impossible to ignore.
Many organizations assume their backups will work, but don’t regularly validate them through real recovery testing. Without routine verification, backups may exist… yet still fail when it matters most (corruption, missing dependencies, misconfigurations, or incomplete restore points).
IDC’s State of Disaster Recovery and Cyber-Recovery 2024-2025 highlights that the challenge is not only technology, it’s capacity. IT leaders cite time and resource availability as one of the top barriers to effective disaster recovery, alongside skills and recovery time objectives.
The resource burden is real. Many organizations spend significant time, every week, managing backups. But the conclusion is unavoidable: testing is non-negotiable. In ransomware scenarios, recovery isn’t a plan, it’s a capability. And capabilities must be verified, repeatable, and proven under pressure.
Scope, Testing, and Restoration Drills
Based on what I lived through, here is the reality and uncomfortable truth:
A backup is only valid the day it has been successfully restored, not just when the monitoring light is green.
Not when the job completes. Not when the dashboard is green. Only when a real restoration has been tested end-to-end.
This is why, in our work on DevOps and critical infrastructure, we insist on:
I turned this personal disaster into professional discipline so it never happens in production environments. At Ivy Partners, in every infrastructure decision, we prioritize:
- What really needs to be recovered? (Scope accuracy)
- Can we actually restore what we claim to back up? (Testing)
- How fast can we go from disaster to operational again? (Documentation and speed)
This isn’t optional. Given the cost of downtime, the prevalence of ransomware, and the existential threat of prolonged data loss, backup and recovery architecture deserves the same strategic attention as security, performance, and scalability.
Now I’ll leave you with a simple question:
When was the last time you tested a full restoration, from encrypted backup all the way to a working application?
If your answer isn’t “recently” or “regularly,” you have a problem disguised as a solution. Your dashboard is green. Your backup job completes. Your compliance checklist is checked.
But your recovery capability is unknown. And when disaster strikes, unknown recovery capability is a luxury you cannot afford.
The future of infrastructure resilience depends on shifting from this statement: “We have backups.” To this reality: “We have tested, documented, and proven recovery.”
Everything else is just faith masquerading as architecture.
About the Author
Matthieu Eynard Longuet is Storage Engineer (Architecture & DevOps) at Ivy Partners. He is currently designing and operating mission‑critical storage and backup platforms for a leading global private bank.
With a foundation in software and game development, as well as extensive hands‑on homelab experimentation, Matthieu brings a builder’s mindset and an open‑source ethos to enterprise infrastructure. He combines robust hardware with modern automation to deliver resilience, performance, and reliability across complex, multi‑datacenter environments.
Bridging architecture and engineering, he applies DevOps and reliability practices to high‑stakes systems while continuously learning, experimenting, and sharing knowledge. From virtual worlds to petabyte‑scale banking platforms, his focus remains constant: stability, optimization, and building things the right way.